Bilgisayarlara Robot Olmadığımızı İspatlarken Arka Planda Captcha'nın Yaptıkları
bilgisayarlara robot olmadığımızı ispatladığımızda the new york times, google ve google maps için çalışıyor olmamız gerçeği...
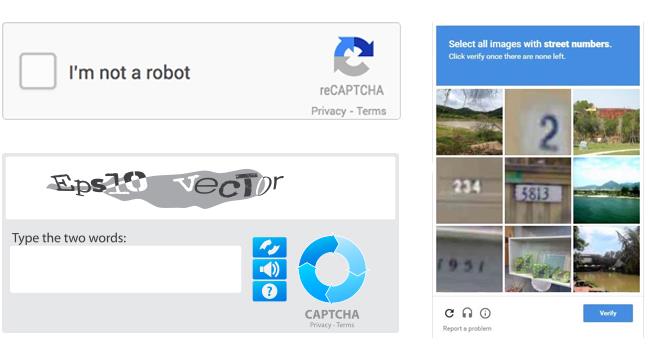
duolingo'nun yaratıcısı luis von ahn, 2000'lerin başında carnegie mellon üniversitesi'nde hocadır. bir gün üniversiteye konuşmacı olarak yahoo'nun bilim ve araştırma departmanın başındaki isim udi manber gelir. udi, yahoo'nun bir türlü çözemediği sorunlardan bahseder: bu sorunlardan bir tanesi, insanların yazdıkları programları kullanarak yahoo'dan yüzlerce, binlerce, hatta milyonlarca e-mail hesabı almasıdır. bilgisayar bunu yapanın bir insan mı yoksa bir bilgisayar programı mı olduğunu ayırt edememektedir. konuşmayı dinleyen luis von ahn bunun bir test ile çözülebileceğini düşünür ve captcha sistemini bulur çünkü o zamanlar (ve hatta hala) bilgisayarlar "eciş bücüş" bozulmuş harf ve sayıları okumakta zorlanmaktadır fakat insanlar için bu bir sıkıntı değildir.
test işe yarar, bir çok websitesi testi kullanır; ilk zamanlarda günde ortalama 200 milyon captcha girilmektedir. bu kadar type edilen yazı, bu insan gücü bir işe yaramalıdır, ziyan edilmemelidir. o dönemler the new york times ve google, eski kitap ve dökümanları dijital ortama taşımaktadır fakat bu işlem için kullanılan bilgisayar programları net taranamamış yamuk yumuk çıkmış yazıları okumakta, anlamakta ve dijital olarak yazmakta zorlanır. luis von ahn'nin aklına bir fikir gelir; bu bilgisayar tarafından okunamayan görüntüleri insanlara captcha olarak sunalım, boş boş yazmasınlar ve bir işe yarasınlar.
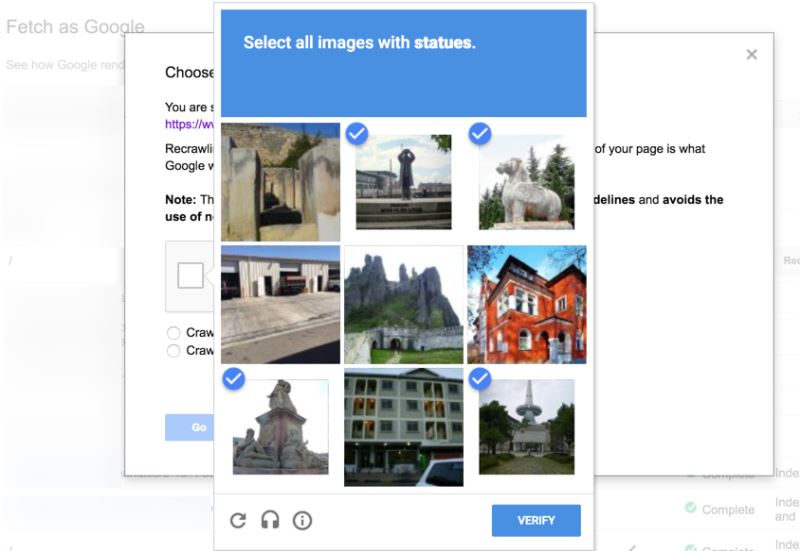
benzer bir taktiği google maps de kullanır. robot olmadığımızı ispatlamak amacıyla; park yeri, trafik işareti, köprü, trafik lambası, ağaç, araba, yaya geçiti vs. içeren resimlere tıkladığımızda, map oluştururken bazı görselleri algılayamayan bilgisayarlara yardımcı oluyoruz!
luis von ahn bu win win yaklaşımından duolingo'da da faydalanır. buzzfeed ve diğer haber siteleriyle anlaşıp, bu sitelerin çevirilerini, practice amaçlı, duolingo ile dil öğrenenlere yaptırır.
bu pragmatik yaklaşımı takdir etmek ve ufkumu açmak dışında elimden bir şey gelmiyor.
kaynak podcast
ekleme 1: en basit şekilde işin mantığını açıklarsak bilgisayarı kandırmak için yazılmış botlar (robotlar yani) yazıları okuyamıyor, insanlar okuyabiliyor ve tabii ki testi sunan sistem captcha doğrulama yetişine sahip. örneğin re-captcha'yı soran sistem/bilgisayar kutucuk tıklanmadan önce mouse'un hareket edişinden tıklayan bir insan mı yoksa yazılmış bir bot (robot) mu anlayabiliyor. çünkü insanlar tıklamadan önce mouse'u rastgele, dalgalı (wiggly) hareket ettiriyor, refleks olarak. bu da küçük ufuk açıcı bilgi.
ekleme 2: şu soru çok gelmiş: testi sunan bilgisayar onaylamak için doğru cevabı zaten bilmek zorunda o zaman bize gerek yok. ben uzman değilim fakat kazın ayağı öyle değil gibi. reverse turing test biraz karışık bir konu ama benim anladığım şu; aynı captcha'yı birden fazla kişiye sorup en çok type edilen yazıyı doğru kabul ediyor. kimi sistemde de image recognition var, yani bazı eciş bücüş çizgilerin harfe ya da sayıya denk geldiğini biliyor bilgisayar fakat bu çizgiler bir araya geldiğinde okuyamıyor. yani doğru cevap generate edemiyor fakat doğrulayabiliyor. zaten artık bu tip captcha pek kullanılmıyor re-captcha var ya da hazır cevaplanmış captcha'lar kullanılıyor. benim yazdığım uygulama 2000'ler başı. o dönemler bazen doğru yazdığınız yanlış, yanlış yazdığınız doğru kabul edilebiliyordu, sistemde sorun vardı. bana bile kaç defa denk geldi. hmmm biraz yaşlanmış olabilirim. podcast'i de dinleyin derim, çok eğlenceli uzun da değil.
Farkında Bile Olmadan Google'a Hediye Ettiğiniz Verilerle İlgili Sizi Ürkütecek Gerçekler